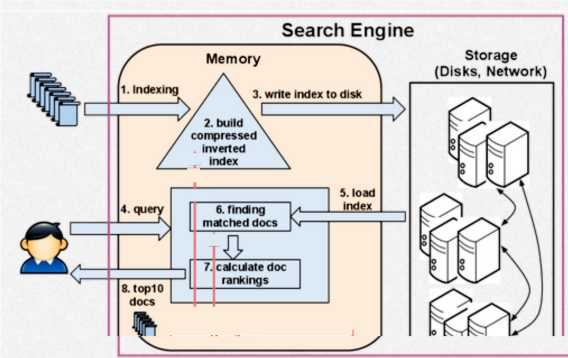
Faze kreiranja invertovanog indeksa
Struktura koja omogućava brzu pretragu po rečima u velikim kolekcijama teksta naziva se invertovani (engl. inverted) indeks. U poređenju sa starijim bibliotečkim sistemima, to bi bilo ekvivalentno vođenju posebne fascikle za svaku moguću reč koja se pojavljuje negde u kolekciji. Reči bi se čuvale leksikografski uređene po korpama. To bi omogućilo bibliotekaru da pronađe fascikle sa spiskom knjiga koje sadrže reči Pariz, devetnaesti, vek. Zatim bi bilo potrebno ispitati te fascikle i pronaći spisak knjiga koje odgovaraju tim rečima - odn. upitu. Taj proces bi trajao različito dugo, u zavisnosti od veličine fascikli, međutim i ovaj proces se može ubrzati ukoliko je spisak knjiga u fasciklama uređen leksikografski ili po nekom drugom principu (npr. serijski broj knjige). U suštini to je ono što se i dešava na računaru.
Indeksiranje
U matematičkom smislu, invertovani indeks je funkcija koja mapira
termin, reč, (engl. term, keyword) na skup dokumenata, obično
predstavljenu kao rastući ili opadajući niz celobrojnih vrednosti koje
predstavljaju serijske brojeve dokumenata. Takva funkcija se na računaru
realizuje pomoću više datoteka.
Algoritam indeksiranja i nastanka eksternih struktura invertovanog
indeksa u najkraćem obliku može se opisati sledećim koracima:
1. inicijalizacija
1. rečnik - indeks sekvencijalna ili rasuta datoteka,
skladišti meta podatke za sve termine, koristi se prilikom
inicijalizacije pretrage
2. invertovana datoteka - sekvencijalna datoteka, sadrži liste dokument
idenfitikatora za termine iz rečnika, koristi se prilikom izvršavanja
pretrage
3. skladište dokumenata - indeks-sekvencijalna datoteka koja se koristi
prilikom učitavanja rezultata pretrage
2. obrada ulaznih podataka
1. učitava se sledeći dokument
2. dodeljuje se serijski broj dokumentu (1, 2, 3...)
3. zapisuje se u skladište pod dodeljenim serijskim brojem
4. vrši se tokenizacija teksta - za svaki termin vodi se lista dokument
identifikatora (serijskih brojeva) u kojima je termin evidentiran
(“foo”: [1, 3], “bar”: [2, 3])
5. ponavlja se korak 2.1 dok se svi dokumenti ne obrade
3. zapisivanje invertovanog indeksa - za sve parove termin, lista:
1. u invertovanu datoteku se zapisuje termin i
njegova lista dokumenata ([foo, 1, 3], [bar, 2, 3])
2. meta podaci o terminu skladište se u rečniku - njih čine sam termin,
pomeraj u primarnoj datoteci, dokument frekvencija, tzv. term
frekvencija i drugi.
Postoje različiti načini da se ovaj proces implementira, a ovdje dati koraci definišu opšti pristup problemu.
copyright M2M
BL-2011/14